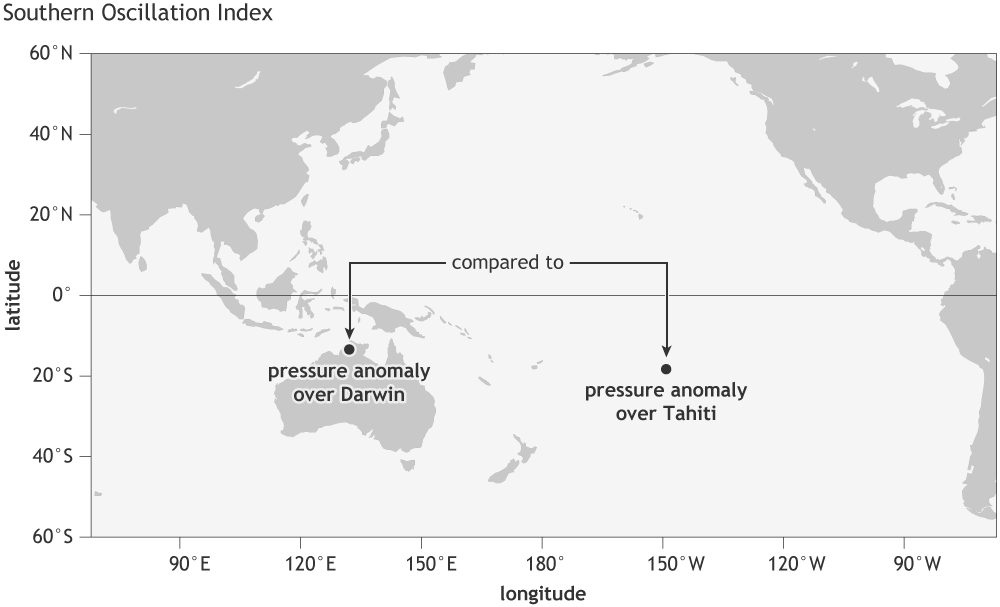
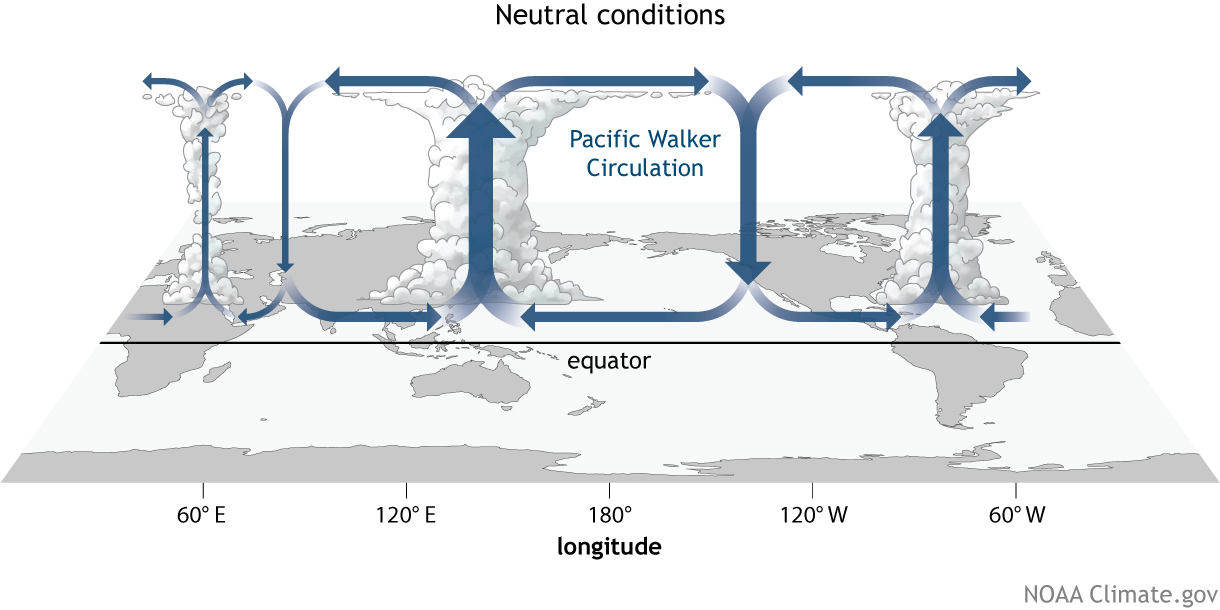
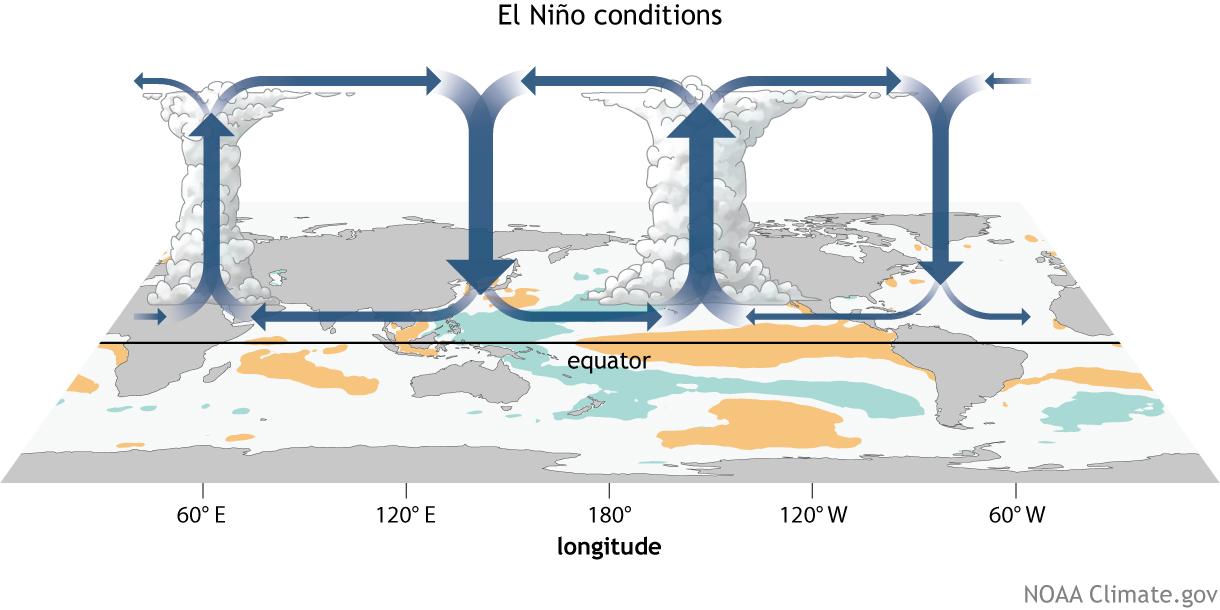
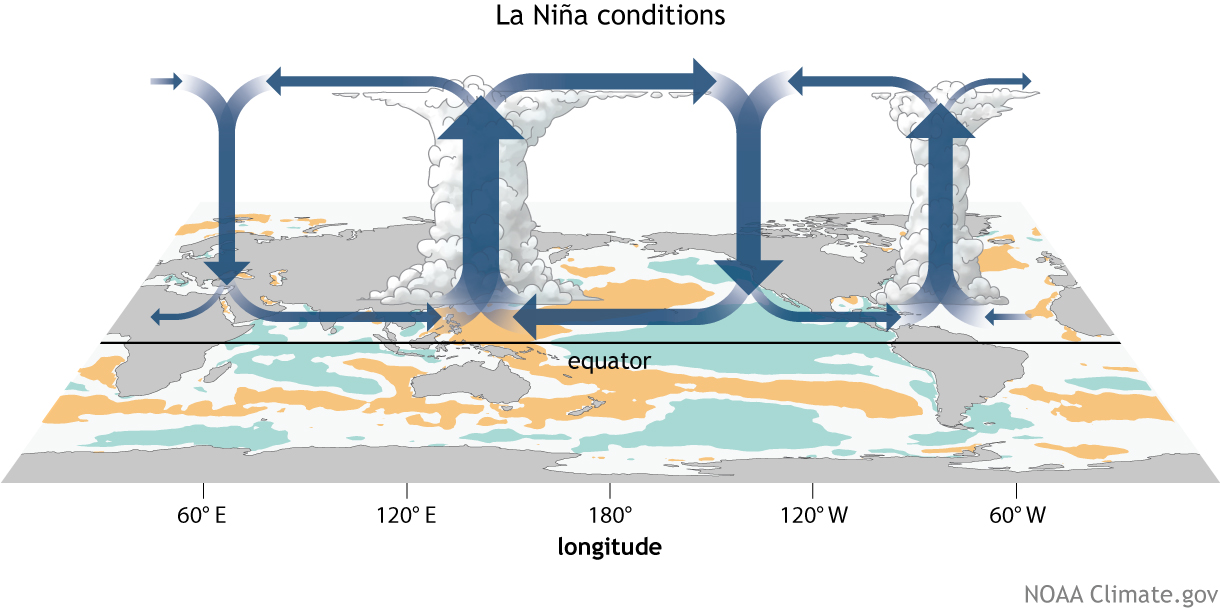
Trabalhar com dados do CMIP5 pode ser um pouco confuso pois nem sempre eles apresentam estruturas iguais. No meu caso eu tenho um conjunto de arquivos de três modelos (CanESM2, CSIRO e HadGEM2) do CMIP5 e estes dados estão dispostos em arquivos de 5-10 anos, ou seja, uma série de 100 anos temos 10-20 arquivos.
Para juntar todos os arquivos em um só eu utilizei o NCO (Netcdf Operator) através do comando ncrcat. O script abaixo irá juntar todos os arquivos, de cada modelo, em apenas um arquivo.
#!/bin/bash
#########################################################
# O nome dos meu arquivos tem a seguinte estrutura:
# tos_Omon_CanESM2_esmHistorical_r1i1p1_199001-200012.nc
# $var $modelos $xpt
#########################################################
dir_inp=( '/dados/data/ESM-PP/SST/Historical/' ) # Diretório
var=( 'tos_Omon' ) # Variável
modelos=( 'CanESM2' 'CSIRO' 'HadGEM2' ) # Pasta/Modelos
xpt=( 'esmHistorical_r1i1p1' ) # Ensemble
# loop para contar o número de arquivos referente a cada modelo
for mdl in ${modelos[@]}; do
# numero de arquivos neste ensemble member
num_arq=$( ls ${dir_inp}${var}_${mdl}_${xpt}*.nc | wc -w )
echo "" $mdl
# se houver apenas um arquivo continue para o próximo loop
if [ ${num_arq} -le 1 ]; then
echo "Há apenas um arquivo em" ${dir_inp}.
continue
fi
echo "Existem" ${num_arq} "arquivos no" ${dir_inp}
# Data inicial de cada arquivo (o nome do primeiro arquivo inclui a data inicial)
yyyymm_in=$( ls ${dir_inp}${var}_${mdl}_${xpt}*.nc | sed -n '1p' | cut -d '_' -f 6 | cut -d '-' -f 1 )
# Data final de cada arquivo ( o nome do último arquivo inclui a data final)
yyyymm_fi=$( ls ${dir_inp}${var}_${mdl}_${xpt}*.nc | sed -n "${fl_nbr}p" | cut -d '_' -f 6 | cut -d '-' -f 2 )
echo $yyyymm_in, $yyyymm_fi
## Juntando todos os arquivs em apenas um só arquivo
ncrcat -O ${dir_inp}${var}_${mdl}_${xpt}*.nc ${dir_inp}${var}_${xpt}_${mdl}_${yyyymm_in}-${yyyymm_fi}
done
exit 0
Este script calculou em primeiro lugar os pesos para cada célula da grade do modelo, antes de usar os pesos para realizar a interpolação cúbica da grade nativa para a nova grade regular. Eu segui as mesmas etapas para todos os meus arquivos e reuniu os comandos em um script que irá varrer todos os arquivos no diretório definido. Os arquivos do CMIP5 estão em formato de Netcdf porém, o espaçamento de grade destes arquivos são diferentes. Portanto, para calcular uma grade retangular genérica para todos os dados para poder comparar os arquivos e executar operações com matrizes a solução foi utilizar o cdo para gerar esta grade retangular, com latitudes de -90 a 90 e longitude de 0 a 360.
Para isto execute estes comandos:
#/bin/sh
modelos=( 'CanESM2' 'CSIRO' 'HadGEM2' ) # Pastas para cada modelo
dir_inp=( '/dados/data/ESM-PP/SST/Historical/$modelos/' )
num_arq=$( ls ${dir_inp}*.nc | wc -w )
echo " Foram encontrados " num_arq " no diretório "
modelos=$( ls *.nc )
for model in ${models[@]}; do
echo "Degradando o modelo: " $model
nome=$( ls $model | cut -d '.' -f 1 )
cdo genbil,r360x180 ${dir_inp}${var}_${xpt}_${mdl}_${yyyymm_in}-${yyyymm_fi} ${dir_inp}${var}_wgts_${xpt}_${mdl}_${yyyymm_in}-${yyyymm_fi}
cdo remap,r360x180,${dir_inp}${var}_wgts_${xpt}_${mdl}_${yyyymm_in}-${yyyymm_fi} ${dir_inp}${var}_${xpt}_${mdl}_${yyyymm_in}-${yyyymm_fi} ${dir_inp}${var}_regular_${xpt}_${mdl}_${yyyymm_in}-${yyyymm_fi}
done
Em seguida, era preciso calcular as médias anuais de TSM em todos os arquivos, pois isso torna um pouco mais fácil de usar comandos do CDO depois. Por isso, foi feito um loop sobre todos os arquivos (nova grade) calculando a média anual. Uma vez que todas as grades nativas são diferentes, e alguns modelos têm valores fill_value ou mascaras isso pode gerar um problema quando você for calcular o ensemble mean. Para não ter problema o programa faz o loop apenas sobre os valores presente em cada ponto de grade e executa a média. Por isso, é necessário definir o intervalo de valores aceitáveis no arquivo que é, do ponto de congelamento da água da superfície do mar até um valor ridiculamente alto. O comando 'setvrange' do cdo cuida disso para nós antes de calcular as médias anuais.
#/bin/sh
modelNumbers=$( ls *.nc | wc -w )
echo "Encontrados " ${modelNumbers}
rm -f YRLYAVG/*.nc
modelos=$( ls *.nc )
for model in ${modelos[@]}; do
echo "Calculando media anual: " $model
name=$( ls $model | cut -d '.' -f 1 )
cdo -setvrange,271.45,320 $model $model.tmp
cdo yearmean -selyear,1950/2005 -selvar,tos $model.tmp ${name}_yrly.nc
rm $model.tmp
cdo sinfo ${name}_yrly.nc
mv ${name}_yrly.nc YRLYAVG/.
done
cd YRLYAVG
Este simples comando calcula o ensemble mean de todos os arquivos de médias anuais cada um representando um cenário do modelo.
cdo ensmean *.nc ensemble_media_historico.nc
Em seguida, repetimos todos esses comandos tanto para as projeções futuras RCP8.5 quanto para os arquivos históricos. Como preparação final desses arquivos antes da análise eu queria estimar a média de longo prazo do ensemble mean. Primeiro, é preciso calcular a climatologia e foi escolhido 1961-1990 como climatologia de referência.
cdo timselavg,30 -seldate,19610101,19900101 ensemble_media_historico.nc ensemble_media_1961_1990.nc
cdo sinfov ensemble_media_1961_1990.nc
cdo sinfov ensemble_media_1961_1990.nc
Estes comandos calcula a climatologia das simulações históricas dos modelos. Em seguida, repete os comandos para os períodos de 2006-2025 e 2025-2050 para obter as projeções futuras.
Boa Sorte e Bom Trabalho a Todos!!